
Published 2024-01-18.
Time to read: 6 minutes.
llm collection.
stable-diffusion-webui
is a powerful and user-hostile user interface for Stable Diffusion by AUTOMATIC1111 that requires a determinated effort to master.
It has a comprehensive wiki.
Documentation is fragmented, and the state of the art is moving very quickly,
so by the time you get up to speed,
everything has changed and you must start the learning process over again.
The previous article, Image Generation With Stable Diffusion, discussed what Stable Diffusion is, defined terminology, and gave an overview. The next article, ComfyUI, discusses the next-generation user interface for Stable Diffusion.
Installation
You can skip this section if you intend to run Stable Diffusion from an online service.
The README provides installation instructions for Windows and Apple Silicon. Because I normally work with Linux, and WSL, but not Mac, this section provides installation instructions for native Ubuntu and Ubuntu on WSL. Perhaps Mac users might find some of my comments helpful. I found that the installation instructions were chaotic and badly done.
Stable Diffusion and various useful other puzzle pieces are automatically installed along with
stable-diffusion-webui.
$ yes | sudo apt install git python3 python3-venv libgl1 libglib2.0-0
Google-perftools includes TCMalloc,
a fast C/C++ memory allocator.
The stable-diffusion-webui uses TCMalloc when available.
You should install it:
$ yes | sudo apt install google-perftools
Clone the Git repository and move into it.
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
$ cd stable-diffusion-webui
You should use a Python virtual environment to hold the proper version of the many Python packages that Stable Diffusion requires. This prevents dependency collisions with other programs. I wrote an article about how to do that.
I discovered that the stable-diffusion-webui scripts are hard-coded to look for a virtual environment called venv.
Create a Python virtual environment called venv within the stable-diffusion-webui directory and activate it like this:
$ python3 -m venv venv
$ source venv/bin/activate
Run webui.sh.
This script clones several Git repositories into the stable-diffusion-webui/repositories subdirectory, including:
-
stable-diffusion-webuibyAUTOMATIC1111. - The core generative LLM.
- The Stable Diffusion Version 2 models.
- BLIP - Bootstrapping Language-Image Pre-training for unified vision-language understanding and generation.
- The k-diffusion generative model.
- The CodeFormer app.
The script eventually calls launch.py, which runs stable-diffusion-webui.
While it is nice to see the program run, we are not done with configuration, so we'll have to stop stable-diffusion-webui,
set a configuration parameter, then relaunch.
$ bash webui.sh ################################################################ Install script for stable-diffusion + Web UI Tested on Debian 11 (Bullseye), Fedora 34+ and openSUSE Leap 15.4 or newer. ################################################################ ################################################################ Running on mslinn user ################################################################ ################################################################ Clone stable-diffusion-webui ################################################################ Cloning into 'stable-diffusion-webui'... remote: Enumerating objects: 30495, done. remote: Total 30495 (delta 0), reused 0 (delta 0), pack-reused 30495 Receiving objects: 100% (30495/30495), 33.36 MiB | 6.79 MiB/s, done. Resolving deltas: 100% (21359/21359), done. ################################################################ python venv already activate or run without venv: /mnt/f/work/llm/stable/venv ################################################################ ################################################################ Launching launch.py... ################################################################ Python 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0] Version: v1.7.0 Commit hash: cf2772fab0af5573da775e7437e6acdca424f26e Installing clip Installing open_clip Cloning Stable Diffusion into /mnt/f/work/llm/stable/stable-diffusion-webui/repositories/stable-diffusion-stability-ai... Cloning into '/mnt/f/work/llm/stable/stable-diffusion-webui/repositories/stable-diffusion-stability-ai'... remote: Compressing objects: 100% (311/311), done. remote: Total 580 (delta 279), reused 452 (delta 248), pack-reused 0 Receiving objects: 100% (580/580), 73.44 MiB | 6.84 MiB/s, done. Resolving deltas: 100% (279/279), done. Updating files: 100% (135/135), done. Cloning Stable Diffusion XL into /mnt/f/work/llm/stable/stable-diffusion-webui/repositories/generative-models... Cloning into '/mnt/f/work/llm/stable/stable-diffusion-webui/repositories/generative-models'... remote: Enumerating objects: 860, done. remote: Counting objects: 100% (513/513), done. remote: Compressing objects: 100% (246/246), done. remote: Total 860 (delta 365), reused 306 (delta 263), pack-reused 347 Receiving objects: 100% (860/860), 42.67 MiB | 7.36 MiB/s, done. Resolving deltas: 100% (436/436), done. Cloning K-diffusion into /mnt/f/work/llm/stable/stable-diffusion-webui/repositories/k-diffusion... Cloning into '/mnt/f/work/llm/stable/stable-diffusion-webui/repositories/k-diffusion'... remote: Enumerating objects: 1329, done. remote: Counting objects: 100% (611/611), done. remote: Compressing objects: 100% (81/81), done. remote: Total 1329 (delta 568), reused 538 (delta 530), pack-reused 718 Receiving objects: 100% (1329/1329), 239.04 KiB | 1.07 MiB/s, done. Resolving deltas: 100% (931/931), done. Cloning CodeFormer into /mnt/f/work/llm/stable/stable-diffusion-webui/repositories/CodeFormer... Cloning into '/mnt/f/work/llm/stable/stable-diffusion-webui/repositories/CodeFormer'... remote: Enumerating objects: 594, done. remote: Counting objects: 100% (245/245), done. remote: Compressing objects: 100% (88/88), done. remote: Total 594 (delta 175), reused 173 (delta 157), pack-reused 349 Receiving objects: 100% (594/594), 17.31 MiB | 2.92 MiB/s, done. Resolving deltas: 100% (286/286), done. Cloning BLIP into /mnt/f/work/llm/stable/stable-diffusion-webui/repositories/BLIP... Cloning into '/mnt/f/work/llm/stable/stable-diffusion-webui/repositories/BLIP'... remote: Enumerating objects: 277, done. remote: Counting objects: 100% (165/165), done. remote: Compressing objects: 100% (30/30), done. remote: Total 277 (delta 137), reused 136 (delta 135), pack-reused 112 Receiving objects: 100% (277/277), 7.03 MiB | 3.12 MiB/s, done. Resolving deltas: 100% (152/152), done. Installing requirements for CodeFormer Installing requirements Launching Web UI with arguments: no module 'xformers'. Processing without... no module 'xformers'. Processing without... No module 'xformers'. Proceeding without it. Style database not found: /mnt/f/work/llm/stable/stable-diffusion-webui/styles.csv Downloading: "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors" to /mnt/f/work/llm/stable/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors 100%|██████████████████████████████████████████████████████| 3.97G/3.97G [00:42<00:00, 101MB/s] Calculating sha256 for /mnt/f/work/llm/stable/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors: Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`. 6ce0161689b3853acaa03779ec93eafe75a02f4ced659bee03f50797806fa2fa Loading weights [6ce0161689] from /mnt/f/work/llm/stable/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors Creating model from config: /mnt/f/work/llm/stable/stable-diffusion-webui/configs/v1-inference.yaml vocab.json: 100%|███████████████████████████████████████████████████████████████| 961k/961k [00:00<00:00, 21.9MB/s] merges.txt: 100%|███████████████████████████████████████████████████████████████| 525k/525k [00:00<00:00, 117MB/s] special_tokens_map.json: 100%|█████████████████████████████████████████████████████████████| 389/389 [00:00<00:00, 4.56MB/s] tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████| 905/905 [00:00<00:00, 10.8MB/s] config.json: 100%|██████████████████████████████████████████████████████████████| 4.52k/4.52k [00:00<00:00, 37.5MB/s] Applying attention optimization: Doggettx... done. Running on local URL: http://127.0.0.1:7860
Model loaded in 32.9s (calculate hash: 9.7s, load weights from disk: 0.9s, create model: 0.7s, apply weights to model: 20.7s, calculate empty prompt: 0.5s).
The installation script launched the Stable Diffusion web user interface. There was no “Installation Successful” message. Instead, there was no output after a while and I could see that CPU usage dropped.
In another console, I listed the PIP dependencies of stable-diffusion-webui:
$ source venv/bin/activate
$ pip list Package Version ---------------------------- -------------------- absl-py 2.1.0 accelerate 0.21.0 addict 2.4.0 aenum 3.1.15 aiofiles 23.2.1 aiohttp 3.9.1 aiosignal 1.3.1 aliyun-python-sdk-core 2.14.0 aliyun-python-sdk-kms 2.16.2 altair 5.2.0 antlr4-python3-runtime 4.9.3 anyio 3.7.1 astunparse 1.6.3 attrs 23.2.0 audioread 3.0.1 av 11.0.0 basicsr 1.4.2 beautifulsoup4 4.12.3 blendmodes 2022 cachetools 5.3.2 certifi 2023.7.22 cffi 1.16.0 chardet 5.2.0 charset-normalizer 3.3.2 clean-fid 0.1.35 click 8.1.7 clip 1.0 cmake 3.28.1 coloredlogs 15.0.1 colorlog 6.8.0 contourpy 1.2.0 controlnet-aux 0.0.6 crcmod 1.7 cryptography 41.0.7 cssselect2 0.7.0 cycler 0.12.1 datasets 2.13.0 decorator 5.1.1 deprecation 2.1.0 diffusers 0.25.1 dill 0.3.6 edge-tts 6.1.9 einops 0.4.1 embreex 2.17.7.post4 face-alignment 1.3.5 facexlib 0.3.0 fastapi 0.94.0 ffmpy 0.3.1 filelock 3.13.1 filterpy 1.4.5 flatbuffers 23.5.26 fonttools 4.47.2 frozenlist 1.4.1 fsspec 2023.9.2 ftfy 6.1.3 future 0.18.3 fvcore 0.1.5.post20221221 gast 0.5.4 gdown 4.7.3 gfpgan 1.3.8 gitdb 4.0.11 GitPython 3.1.32 google-auth 2.26.2 google-auth-oauthlib 1.2.0 google-pasta 0.2.0 gradio 3.41.2 gradio_client 0.5.0 grpcio 1.60.0 h11 0.12.0 h5py 3.10.0 handrefinerportable 2024.1.18.0 httpcore 0.15.0 httpx 0.24.1 huggingface-hub 0.20.2 humanfriendly 10.0 idna 3.6 imageio 2.33.1 imageio-ffmpeg 0.4.9 importlib-metadata 7.0.1 importlib-resources 6.1.1 inflection 0.5.1 invisible-watermark 0.2.0 iopath 0.1.9 Jinja2 3.1.3 jmespath 0.10.0 joblib 1.3.2 jsonmerge 1.8.0 jsonschema 4.21.0 jsonschema-specifications 2023.12.1 keras 2.15.0 kiwisolver 1.4.5 kornia 0.6.7 lark 1.1.2 lazy_loader 0.3 libclang 16.0.6 librosa 0.8.0 lightning-utilities 0.10.1 lit 17.0.6 llvmlite 0.41.1 lmdb 1.4.1 lpips 0.1.4 lxml 5.1.0 mapbox-earcut 1.0.1 Markdown 3.5.2 markdown-it-py 3.0.0 MarkupSafe 2.1.3 matplotlib 3.8.2 mdurl 0.1.2 mediapipe 0.10.9 ml-dtypes 0.2.0 mmcv-full 1.7.0 mmdet 2.26.0 modelscope 1.9.3 mpmath 1.3.0 multidict 6.0.4 multiprocess 0.70.14 networkx 3.2.1 numba 0.58.1 numpy 1.23.5 nvidia-ml-py 12.535.133 nvitop 1.3.0 oauthlib 3.2.2 omegaconf 2.2.3 onnx 1.15.0 onnxruntime 1.16.3 open-clip-torch 2.20.0 opencv-contrib-python 4.9.0.80 opencv-python 4.9.0.80 opencv-python-headless 4.8.1.78 opt-einsum 3.3.0 orjson 3.9.12 oss2 2.18.4 packaging 23.2 pandas 2.1.4 piexif 1.1.3 Pillow 9.5.0 pip 23.2 platformdirs 4.1.0 pooch 1.8.0 portalocker 2.8.2 protobuf 4.23.4 psutil 5.9.5 py-cpuinfo 9.0.0 pyarrow 14.0.2 pyarrow-hotfix 0.6 pyasn1 0.5.1 pyasn1-modules 0.3.0 pycocotools 2.0.7 pycollada 0.8 pycparser 2.21 pycryptodome 3.20.0 pydantic 1.10.14 pydub 0.25.1 Pygments 2.17.2 PyMatting 1.1.12 pyparsing 3.1.1 PySocks 1.7.1 python-dateutil 2.8.2 python-multipart 0.0.6 python-slugify 8.0.1 pytorch-lightning 1.9.4 pytz 2023.3.post1 PyWavelets 1.5.0 PyYAML 6.0.1 realesrgan 0.3.0 referencing 0.32.1 regex 2023.12.25 rembg 2.0.50 reportlab 4.0.9 requests 2.31.0 requests-oauthlib 1.3.1 resampy 0.4.2 resize-right 0.0.2 rich 13.7.0 rpds-py 0.17.1 rsa 4.9 Rtree 1.2.0 safetensors 0.3.1 scikit-image 0.21.0 scikit-learn 1.4.0 scipy 1.11.4 seaborn 0.13.1 segment-anything 1.0 semantic-version 2.10.0 sentencepiece 0.1.99 setuptools 68.1.2 shapely 2.0.2 simplejson 3.19.2 six 1.16.0 slugify 0.0.1 smmap 5.0.1 sniffio 1.3.0 sortedcontainers 2.4.0 sounddevice 0.4.6 soundfile 0.12.1 soupsieve 2.5 starlette 0.26.1 supervision 0.17.1 svg.path 6.3 svglib 1.5.1 sympy 1.12 tabulate 0.9.0 tb-nightly 2.16.0a20240119 tensorboard 2.15.1 tensorboard-data-server 0.7.2 tensorflow-cpu 2.15.0.post1 tensorflow-estimator 2.15.0 tensorflow-io-gcs-filesystem 0.35.0 termcolor 2.4.0 terminaltables 3.1.10 text-unidecode 1.3 tf_keras-nightly 2.16.0.dev2024011910 thop 0.1.1.post2209072238 threadpoolctl 3.2.0 tifffile 2023.12.9 timm 0.9.2 tinycss2 1.2.1 tokenizers 0.13.3 tomesd 0.1.3 tomli 2.0.1 toolz 0.12.0 torch 2.0.1+cu118 torchdiffeq 0.2.3 torchmetrics 1.3.0.post0 torchsde 0.2.6 torchvision 0.15.2+cu118 tqdm 4.66.1 trampoline 0.1.2 transformers 4.30.2 trimesh 4.0.10 triton 2.0.0 typing_extensions 4.9.0 tzdata 2023.4 ultralytics 8.1.3 urllib3 2.1.0 uvicorn 0.26.0 vhacdx 0.0.5 wcwidth 0.2.13 webencodings 0.5.1 websockets 11.0.3 Werkzeug 3.0.1 wheel 0.42.0 wrapt 1.14.1 xxhash 3.4.1 yacs 0.1.8 yapf 0.40.2 yarl 1.9.4 zipp 3.17.0
You can ensure that the Python virtual environment will be activated each time you run stable-diffusion-webui
by modifying webui-user.sh, which was installed when you cloned the repository.
This is how the file looks by default; every line is commented out:
1: #!/bin/bash 2: ######################################################### 3: # Uncomment and change the variables below to your need:# 4: #########################################################
5: # Install directory without trailing slash 6: #install_dir="/home/$(whoami)" 7: 8: # Name of the subdirectory 9: #clone_dir="stable-diffusion-webui" 10: 11: # Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention" 12: #export COMMANDLINE_ARGS="" 13: 14: # python3 executable 15: #python_cmd="python3" 16: 17: # git executable 18: #export GIT="git" 19: 20: # python3 venv without trailing slash (defaults to ${install_dir}/${clone_dir}/venv) 21: #venv_dir="venv" 22: 23: # script to launch to start the app 24: #export LAUNCH_SCRIPT="launch.py" 25: 26: # install command for torch 27: #export TORCH_COMMAND="pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113" 28: 29: # Requirements file to use for stable-diffusion-webui 30: #export REQS_FILE="requirements_versions.txt" 31: 32: # Fixed git repos 33: #export K_DIFFUSION_PACKAGE="" 34: #export GFPGAN_PACKAGE="" 35: 36: # Fixed git commits 37: #export STABLE_DIFFUSION_COMMIT_HASH="" 38: #export CODEFORMER_COMMIT_HASH="" 39: #export BLIP_COMMIT_HASH="" 40: 41: # Uncomment to enable accelerated launch 42: #export ACCELERATE="True" 43: 44: # Uncomment to disable TCMalloc 45: #export NO_TCMALLOC="True" 46: 47: ###########################################
Modify line 21 above by uncommenting it and providing the name of the directory for the Python virtual environment. This is what it looks like for me:
# python3 venv without trailing slash (defaults to ${install_dir}/${clone_dir}/venv)
venv_dir="venv"
I found that I had to install one dependency manually:
$ pip install insightface
With the above done, the Stable Diffusion models stored in stable-diffusion-webui/models/Stable-diffusion,
like v1-5-pruned-emaonly.safetensors,
are now accessible to ComfyUI.
Models
- The Stable Diffusion XL (SDXL) model is an upgrade to the celebrated v1.5 and the forgotten v2 models. It has four times the native resolution (1024x1024 instead of 512x512), and higher image quality. Read Tips on using SDXL 1.0 model.
To install the above models in AUTOMATIC1111, put the base and the refiner models in
stable-diffusion-webui/models/Stable-diffusion.
Launch
Press CTRL-C in the console that is running Stable Diffusion.
This time the settings in webui-user.sh
should be active.
You have two choices for launching Stable Diffusion:
-
Run the installer,
webui.sh, each time you want to run Stable Diffusion. This has the benefit of ensuring you have the latest version of all dependencies, at the expense of a long startup, and the potential for problems. -
Activate the Python virtual environment and then run
launch.py. This is the fastest way to run Stable Diffusion. The current directory must be the directory containinglaunch.py, or it will fail with a lot of error messages. This does not completely suppress all checks for dependencies.Shell$ source venv/bin/activate
$ python launch.py Python 3.11.5 (main, Sep 11 2023, 13:54:46) [GCC 11.2.0] Version: v1.7.0 Commit hash: cf2772fab0af5573da775e7437e6acdca424f26e Collecting protobuf<=3.9999,>=3.20 Using cached protobuf-3.20.3-py2.py3-none-any.whl (162 kB) Installing collected packages: protobuf Attempting uninstall: protobuf Found existing installation: protobuf 4.23.4 Uninstalling protobuf-4.23.4: Successfully uninstalled protobuf-4.23.4 Successfully installed protobuf-3.20.3 Installing requirements for diffusers is_installed check for tensorflow-cpu failed as 'spec is None' Installing requirements for easyphoto-webui Installing requirements for tensorflow Launching Web UI with arguments: 2024-01-21 12:15:04.591410: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. no module 'xformers'. Processing without... no module 'xformers'. Processing without... No module 'xformers'. Proceeding without it. Style database not found: /mnt/f/work/llm/stable-diffusion/stable-diffusion-webui/styles.csv [-] ADetailer initialized. version: 24.1.1, num models: 9 2024-01-21 12:15:15,008 - modelscope - INFO - PyTorch version 2.1.2+cu121 Found. 2024-01-21 12:15:15,016 - modelscope - INFO - TensorFlow version 2.15.0.post1 Found. 2024-01-21 12:15:15,016 - modelscope - INFO - Loading ast index from /home/mslinn/.cache/modelscope/ast_indexer 2024-01-21 12:15:15,031 - modelscope - INFO - Loading done! Current index file version is 1.9.3, with md5 21e6e6c8a076123c373accfeb616f75f and a total number of 943 components indexed [sd-webui-breadcrumbs v0.8.0] Loading settings UI... [sd-webui-breadcrumbs v0.8.0] Finished. ControlNet preprocessor location: /mnt/f/work/llm/stable-diffusion/stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads 2024-01-21 12:15:16,825 - ControlNet - INFO - ControlNet v1.1.432 2024-01-21 12:15:17,134 - ControlNet - INFO - ControlNet v1.1.432 Loading weights [6ce0161689] from /mnt/f/work/llm/stable-diffusion/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`. Applying attention optimization: Doggettx... done. Model loaded in 25.5s (load weights from disk: 1.5s, create model: 0.3s, apply weights to model: 23.3s, load textual inversion embeddings: 0.2s, calculate empty prompt: 0.1s).
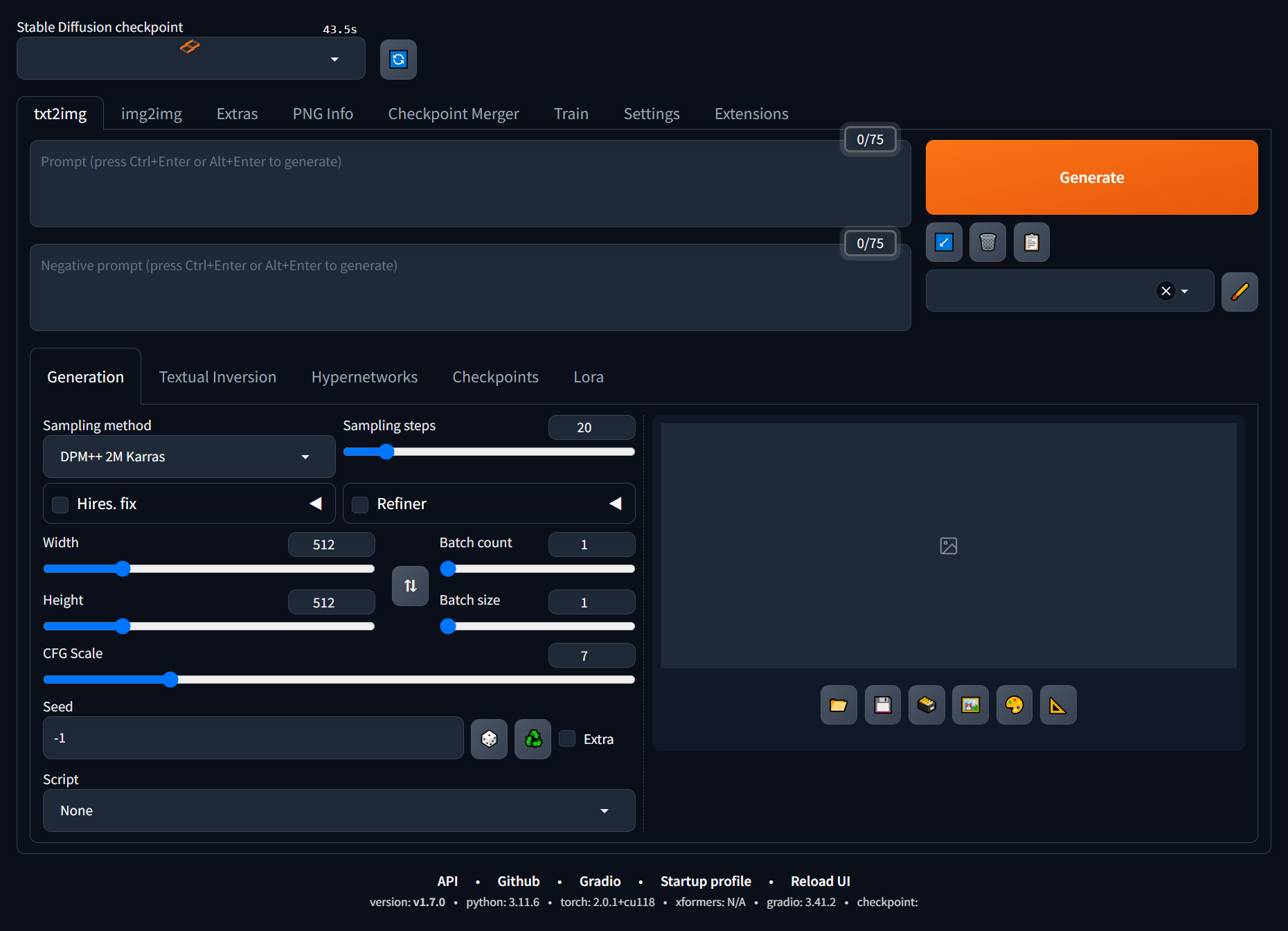
Working with Stable Diffusion
Once the installation process completed,
I pointed my web browser at localhost:7860 and saw from the small orange rotating icon that it was slowly building a checkpoint.
That completed after a few minutes.
Img2img is table stakes for generative AI, and the next YouTube video does an excellent job of teaching it.
I wonder if ControlNet works similarly in stable-diffusion-webui
as in ComfyUI?
Prompts and Images
I typed “a baby's arm holding an apple” into the Prompt area and after a few seconds, the following image appeared:

It works quite well, without any censorship.
However, to generate the desired image, prompt creation can be quite involved.
Often the generated image is strange, unnatural or even disgusting.
Here is an example of a woman with 2 heads, from
ameets21 on huggingface.co:

I have a script that tries to fix hands in some generated art. It uses
clipseg to create a mask around hands and then runs a loop generating new inpainted versions of the input image.
I do not believe that I can influence how well it draws hands;
I can simply have it generate a ton of variants and weed through them to find the best random result.
I added negative prompting influenced by the O.P.'s comment: "poorly drawn hands, poorly rendered hands, bad composition, mutated body parts, disfigured, bad anatomy, deformed body features, deformed hands".
This had basically zero effect on the quality of hand generation. Sure it made every seed produce a different result, but they were no better or worse than without that text included. I also tried the stable diffusion 1.5 model and the 1.5 inpainting model. The inpainting model was horrendous, mostly producing complete garbage, but once out of about 20 tries it produced a nearly perfect hand. That was unexpected, and I think just random chance. I think that the reason that the inpainting model did so poorly is because the original image was generated with a different checkpoint and the inpainting checkpoint wanted to see "very different things" than the original checkpoint would have seen.
... Negative prompts definitely have value; but I don't think that the model "understands" what people think it does. "Deformed hands" means nothing to the model. It just pushes things in a random direction.
Positive Prompts
Adding (parentheses) around selected text for emphasis can help. ((Nested parentheses)) are more emphatic. (((Triple-nested parentheses))) might yield diminishing results.
Example: rule of thirds, golden ratio, (smile)
Negative Prompts
Common negative prompts.Clip Interrogator
Clip Interrogator analyses an image and generates prompt text based on that image. It uses the prompt in Stable Diffusion to generate a set of 4 images. You can put the best image back into Clip Interrogator, iteratively.
Stable Diffusion Prism
I intend to look into this:
sd-prism
Finetuned Diffusion
I intend to look into this:
finetuned_diffusion
Extensions
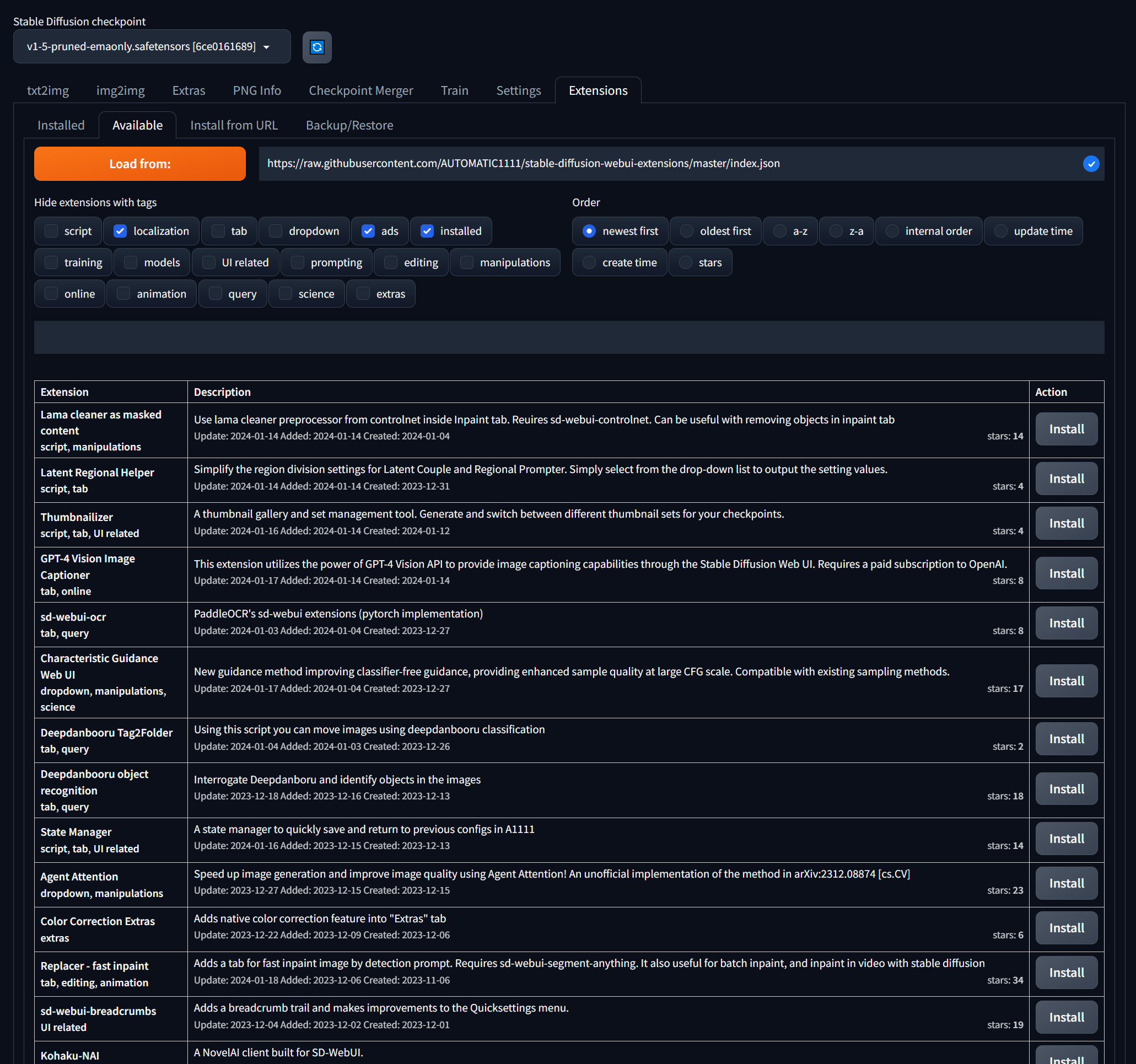
You can browse and install extensions by visiting the Extensions tab, then opening the Available subtab.
This URL will be displayed: raw.githubusercontent.com/.
Click on the orange Load from: button to load information about the available extensions.
Each extension has a Install button on the right.
Dependencies are not automatically installed.
For example, sd-webui-lama-cleaner-masked-content,
and several other extensions,
require sd-webui-controlnet.
You must notice the dependency in the comments, and install both, or sd-webui-lama-cleaner-masked-content will fail.
The extensions can be sorted by age, alphabetically, when updated, when released, and by the number of stars. Sorting by stars quickly reveals the most popular extensions. Here are a few:
- SadTalker - animates still images based on audio input. It syncs facial movements and expressions in an image to match the spoken words in an audio clip, effectively bringing the image to life.
- FaceChain - a deep-learning toolchain for generating your Digital-Twin. With a minimum of 1 portrait-photo, you can create a Digital-Twin of your own and start generating personal portraits in different settings
-
sd-webui-agentattention.git- speeds up image generation with improved image quality using Agent Attention. -
sd-webui-breadcrumbs- adds a breadcrumb trail to the Quicksettings menu. -
sd-webui-controlnet- controls image generation in Stable Diffusion by adding extra conditions. -
sd-webui-lama-cleaner-masked-content- -
sd-webui-replacer- automates objects masking by detection prompt, usingsd-webui-segment-anything, andimg2imginpainting in one easy-to-use tab. It also useful for batch inpaint, and inpaint in video with stable diffusion. -
sd-webui-segment-anything- - EasyPhoto - provides easy photo generation with an online-trained LoRA model that guarantees high-quality output images closely relevant to the input.
- !After Detailer - Automatic detection, masking and inpainting tool for details
-
stable-diffusion-webui-rembg- Removes backgrounds from pictures..
After an extension is installed the model is scanned, which might take several minutes.
LoRA Models
LoRA (Low-Rank Adaptation) models is a training technique for fine-tuning Stable Diffusion models. LoRA offers a good trade-off between file size and training requirements.
LoRA models must be used with model checkpoint files. LoRA modifies styles by applying small changes to the accompanying model file.
civitai.com hosts a large collection of LoRA models.
Apply the LORA filter to see only LoRA models.
The Lora tab of the stable-diffusion-webui showed me that I should store
LoRA models in /mnt/f/work/llm/stable/stable-diffusion-webui/models/LyCORIS.
Laura Carnevali made a good video explanation of LoRA:












