
Published 2025-11-08.
Last modified 2025-11-10.
Time to read: 16 minutes.
llm collection.
- Claude Code Is Magnificent, But Claude Desktop Is a Hot Mess
- Gemini vs. Sonnet 3.5 and 4.6 for Meticulous Work
- Google Gemini Code Assist
- Google Antigravity
- Aider: AI Pair Programming in Your Terminal
- AI Planning vs. Waterfall Project Management
- Best Local LLMs for Coding
- Running an LLM on the Windows Ollama app
- Early Draft: Multi-LLM Agent Pipelines
- MiniMax-M2 and Mini-Agent Review
- MiniMax Web Search with ddgr
- LLM Societies
- CodeGPT
This article examines the economic viability of renting versus purchasing GPUs for Large Language Model (LLM) workloads in Canada. The factors involved in choosing the type of GPU for a given application are discussed, and prices are compared for local versus remote GPUs.
Buying a high-end consumer GPU, like the NVIDIA RTX 4090 (≈$4,500 CAD), or a similarly priced datacentre model like the NVIDIA L4 is rarely cost-effective.
This article computes breakeven points for buying vs renting to show why the previous statement is true for most Canadians. An analysis shows that after accounting for local infrastructure costs, the break-even point is equal to or greater than the expected lifespan of the GPU (2.1–5.0 years).
Remote regions require special consideration. Regional resource pooling and maintaining low-latency internet are key considerations for LLM deployment across Canada. However, the article does not discuss regional resource pooling. Perhaps I will discuss that in the future in another article or two.
While the geographic focus of this article is Canada, the information presented is applicable throughout the world. While costs may vary somewhat elsewhere, the economic arguments presented are likely to remain valid for most geographic regions.
GPU Usage Characteristics
GPUs are generally used for several different purposes:
- Generating video for gaming and simulation video displays
- Peforming cryptocurrency computations
- Running LLMs
Each type of usage uses different aspects of a GPU. This means, for example, that a GPU optimized for gaming is the result of different design trade-offs than a GPU optimized for running LLMs.
, optimized for gaming")
Whereas GPUs used for gaming must be embedded in the gaming system, GPUs used for cryptocurrency and LLMs can be remote with only modest communication requirements between the computers and their remote GPUs, because the GPUs do not actually need to generate video.

For example, the NVIDIA L4 GPU is a single-slot card that does not require any additional power connectors because its power draw is rated at only 72 W maximum, which is 80% less than the power draw of an RTX 4090. Like all datacentre GPUs, the L4 has no display ports because it is not designed to have monitors connected to it. Like all of the NVIDIA GPUs mentioned, the L4 has a PCI-Express 4.0 x16 interface.

Just like CPUs, GPUs can run several programs at once. To achieve this, GPUs dynamically dedicate portions of their memory and allocate processing power for each program that they are running. This means that if you run a demanding video game, even a powerful GPU may not be able to run large LLMs at the same time as servicing the game with acceptable performance.
Swapping between VRAM and RAM
Most GPUs employ memory swapping to free up space in the VRAM for the LLM models and data that need to run next. This process is also known as using virtual memory, and it allows a GPU to run more applications than it could with its physical memory alone. GPU swapping involves moving memory contents between system RAM and GPU VRAM.
The GPU bus interface of both the RTX 3060 and the RTX 4090 is PCIe 4.0 x16. GPU swap time increases when the CPU is heavily loaded. This is because that layer swapping is a process that relies heavily on the PCIe bus for data transfer, and the CPU plays a critical role (scheduling and executing the necessary PCIe transfer commands) in managing these transfers.
The NVIDIA RTX 3060 has 12 GB DDR5 VRAM. Swapping on such a system should take 200–800 ms per layer, unless the CPU is overloaded.
A full model swap is not usually required. Good thing, because an RTX 3060 takes 600-800 ms to fully flush its VRAM, and a full reload takes another 800-1200 ms. The total time to fully flush the VRAM of an RTX 3060 and reload all 12 GB is ~1.8 seconds! Snappy response is essential to a user’s perception of the usability of a computer program.
Swapping costs include VRAM offloading latency and memory paging overhead. The LLM VRAM Calculator for Self-Hosting provides good qualitative and quantitative explanations.
In comparison, the NVIDIA RTX 4090 has twice as much VRAM (24 GB GDDR6X) as the RTX 3060, and the transfer rate of the 4090 is 3x faster than the 3060. The result is that swapping on a 4090 is both less likely and faster when required. For example, swapping on a 4090 requires only 70–280 ms per layer, provided the PCIe bus is not the bottleneck.
AHEAD Optio L100 2U

The L100 model advertised by Lambda Labs is not an NVIDIA product. It is expected to be available in December 2025. AHEAD makes the Optio L100 2U Platform with IGX components from NVIDIA.
Unlike every other GPU described in this article, the L100 is an entire system, including a chassis, power supply, etc. The actual purchase cost of every other option needs to be adjusted upward to account for that.
A dozen other vendors also make products using IGX. These vendors typically target industries such as robotics, healthcare (surgical systems), autonomous machinery, and smart manufacturing, where the IGX Thor’s safety features, high performance, and long-term enterprise support are critical.
The NVIDIA IGX Orin 700 platform used in the AHEAD Optio L100 has a unified memory architecture, meaning its GPU and CPU share the same LPDDR5 system memory via a high-speed system memory fabric. However, available memory is reduced to about 52 GB.
| Component | Estimated VRAM/RAM | Notes |
|---|---|---|
| Total Unified Memory | 64 GB LPDDR5 | Shared between CPU and integrated GPU. |
| Estimated OS (IGX-OS) Usage | ~4 GB | Base Linux kernel and core services. |
| Estimated AI Stack Usage | ~8 GB | Drivers, runtimes (Triton, TensorRT), and framework services (Metropolis, Holoscan, etc.). |
| Maximum Available for LLMs | 52 GB | 64 GB - 4 GB - 8 GB |
I asked Gemini to estimate the time to copy 387 MB (an entire layer of floating-point numbers) within this unified memory space, and it suggested the value is likely in the range of 1 to 3 ms, which is significantly faster than the H100's PCIe transfer time of 6-11 ms. Unfortunately, this is misleading. Instead of swapping to system RAM, the IGX must swap to a storage device, several orders of magnitude slower that swapping to system RAM.
The exact price for the AHEAD Optio L100 2U Platform is not publicly listed, as it is an industrial product typically sold through direct sales channels, value-added resellers, or specific quoting processes, with pricing dependent on configuration and support contracts.
The foundational NVIDIA IGX Orin Developer Kit is listed by Canadian retailers for approximately $3,662.52 CAD. The price for a complete AHEAD Optio L100 2U platform is likely to be significantly higher than the base developer kit. Market will determine the price, which might be higher or lower than the developer kit price.
To increase available memory, an NVIDIA RTX 6000 Ada Generation GPU can be added to provide an additional 48 GB. However, this memory would be in a separate address space, so models larger than 52 GB would still not load without swapping to storage. Based on current Canadian retail listings, the price for the NVIDIA RTX 6000 Ada typically falls within the range of $10,180 CAD to $12,700 CAD. This attempt to increase available GPU memory would roughly double the cost, without providing the most desirable benefit (fitting entire huge models into memory).
Still on the trail of how swapping works on the L100, I asked Gemini about swapping between system RAM and NVMe storage. Gemini estimated 500 ms/GB for L100 swap between the System RAM (LPDDR5) and an NVMe SSD. This process is limited by the NVMe drive's read/write speed and raw access latency, which is about 1,000× slower than accessing RAM. Swapping to NVMe introduces a massive delay, typically translating to seconds added to the Time-to-First-Token (TTFT) or causing significant pauses during long inference runs. This mechanism could be used as an emergency capacity extender, but not an aspect of high-performance inference.
Datacentre GPUs for LLM inferencing are evolving rapidly. Capital investments for these types of products require extremely short payback to justify their extreme depreciation. Renting GPUs is probably a much better option than purchasing for most applications.
Introducing Breakeven
It would take over 13 years to pay for a new RTX 4090 or L4 GPU in Canada at current hourly rental rates, running 24/7, based on a street price of around $4,500 CAD. This figure ignores the cost of communication with a remote GPU, the cost of a desktop computer capable of hosting the 4090, and the availability of sufficient electrical power. The remainder of this article goes into those details.
For many scenarios, renting remote GPUs or communal pooling of local GPUs for LLMs makes better economic sense than buying and installing GPUs in individual desktop computers.
Pooling Regional Computing Resources
When considering deployment of LLMs in Canada’s far north and other remote regions, it might be preferable to set up regional computing resources where a collection of GPUs is shared, instead of relying on commercial facilities thousands of miles away. Different architectures could be used for this purpose, but that topic is out of scope for this introductory article.
Several Canadian municipalities and First Nations provide their own internet service, including the City of Calgary, which uses a municipal fibre network for cost savings and reliability. Other examples include Dubreuilville, Ontario, which has its own community-owned high-speed fibre network and TV service, and the Na-Cho Nyäk Dun First Nation, which is building a community-owned telecommunications network in Mayo, Yukon.
I foresee similar community resources for running LLMs throughout Canada, in urban areas as well as remote areas. The economic costs and benefits are compelling.
Local Versus Remote GPUs
Remote GPUs, which are usually rented, run in datacentres and are subject to different economic forces than retail GPUs sold to gamers. This makes the GPUs in datacentres exponentially more expensive to purchase. I am not exaggerating, as you will see in the analysis below. I had to use a log-scale for the cost comparison chart below so you could see all the data points.
However, those datacentre GPUs can be rented for a fraction of the cost of purchasing retail GPUs. This is because datacentres can amortize the cost of their GPUs over many users, and they can optimize power usage, cooling, and space to reduce overall costs.
Furthermore, computers that use remote GPUs instead of physical GPUs can be much less expensive. The decision to install a high-performing GPU in your own computer means the components of the host computer need to be matched with its GPU. This increases the cost of the computer significantly.
- The power supply must be extra large to support the GPU’s demanding power draw.
- The motherboard must provide a usable high-performance PCIe slot, and the GPU/video card is so wide that the two neighbouring slots can be inaccessible.
- The CPU must be powerful enough to providing data quickly
- The computer chassis needs extra cooling to dissipate the heat generated by a powerful GPU.
- Powerful GPUs have fans that can get quite loud when working hard.
Video cards have GPUs with lots of support circuitry for high performance video generation. LLMs do not need that circuitry, so a large and high-value portion of the GPU is wasted if you are not a gamer.
Expensive to buy,
cheap to rent
One of the main points made in this article is that it is surprisingly inexpensive for a lowly laptop or crappy old desktop computer to directly access rented datacenter-class remote GPUs for snappy, insightful responses. The computers would not need to be powerful because the heavy lifting would be done remotely.
Desktop GPU Value Comparison for LLMs
LLM models need at least one GPU to run on, and GPUs are expensive. This section focuses on retail desktop GPUs installed in a desktop computer for the purpose of running LLMs. The next section considers renting remote GPUs for running LLMs.
Best value is defined as the highest tokens/second per dollar (t/s/$) for a given LLM, considering new retail prices as of November 2025.
The t/s/$ (tokens per second per dollar) metric can be misleading. Not all tokens are equal. For example, a 7B model cannot provide the same accuracy or complexity as a 70B model. I view comparative t/s/$ with suspicion unless I know that the same LLM was used to generate all tokens.
The best value consumer-grade GPUs available today for the LLM models discussed in this article are:
The NVIDIA RTX 3060 is the value winner! The 3060’s 12 GB VRAM handles 7B–14B models fully at Q5/Q4 quantization (e.g., GLM-9B at ~55–75 t/s, Qwen3-14B at ~35–50 t/s) and supports 30B models like Qwen3-30B with minimal offload (~20–30 t/s).
The NVIDIA RTX 3090 (24 GB GDDR6X VRAM) provides the best tokens/second per dollar (t/s/$) among new 24 GB GPUs as of November 2025. It enables full Q5/Q4 loads for up to 30B models (~70–100 t/s averaged across sizes, 4K–8K context) without offload, outperforming pricier options like the RTX 4090 in cost-efficiency. Its Ampere architecture delivers ~70–80% of the 4090 inference speed with all of the CUDA support necessary for running LLMs.
An RTX 3090 would approximately double the performance over the RTX 3060 on 30B LLMs (e.g., from 20–30 t/s to 50–70 t/s) at excellent value (0.08–0.11 t/s/$). The 3090 is widely available, relatively power-efficient for a consumer GPU (350W), and should be competitive for about 2 years.
The NVIDIA RTX 4090 is the value runner-up for 24 GB GPUs. This GPU delivers 2 to 3 times faster speeds than the 3060 (a marginal increase over the 3090), but it costs 6 to 8 times more than the 3060 to purchase. However, the price structure for renting remote GPUs is very different, as discussed in the next section.
Multi-GPU Computers
I discuss how a desktop computer could use one GPU primarily for display and a second GPU for LLM computation in
computers.mslinn.com.
This is Gojira, my sweet Ubuntu server, just before I install two NVIDIA 3060 GPUs. One 3060 will replace the GTX 1650 that was previously installed, and the other 3060 will be dedicated to compute-only tasks, such as running LLMs.
I am currently subscribing to Anthropic Pro, MiniMax-M2, eazyBackup, RackSpace, AWS, and free GitHub. While some compute must be done online, I want to perform as much locally as possible without spending much. I am attempting to optimize value-per-dollar, not minimum dollars, or maximum ego gratification.

Renting Remote GPUs
On-demand remote virtualized GPUs can save 90% of the cost of a heavy user of Anthropic, Open AI, Google, etc. Running commercial LLMs is much more expensive than running open source LLMs, and introduces issues such as privacy and data sovereignty.
Renting time on remote GPUs is a quick, simple, easy, and cost-effective way to set up LLMs, provided sufficient internet bandwidth is available. It also requires much less electrical power at the usage location than installing GPUs remotely.
Scaleway and Hivenet both offer attractive pricing. For example, HiveNet offers 5 hours of dedicated NVIDIA 4090 GPU time with 24 GB VRAM for €1 ($1.62 CAD). That really opens up possibilities. Unfortunately, neither of these European vendors have datacentres in North America, so latency is a problem. The Canadian Vendors section below shows vendors that have Canadian datacentres.
It would take approximately 160 months (over 13 years) to pay for a new RTX 4090 GPU in Canada at a rate of €1 ($1.62 CAD) per hour, running 24/7, based on a typical price of around $4,500 CAD. Clearly, renting GPUs for LLMs makes much more economic sense than buying.
Desktop / Datacentre GPU Comparison
GPUs used in datacentres differ from desktop GPUs primarily in their design for large-scale, continuous workloads versus gaming or general use. While desktop GPUs prioritize features for single-machine entertainment like video outputs, datacentre GPUs tend to feature more VRAM and higher bandwidth, a focus on reliability and longevity for 24/7 operation, and specialized hardware for computational tasks like AI and HPC.
The maximum VRAM possible for NVIDIA A10 and L4 is the same: 24 GB. The NVIDIA L4 is a newer, more efficient GPU for LLMs that fit into memory, while the NVIDIA A10 is better for working with large LLMs that require extensive swapping.
Note that the 4090 has a 250ms swap time, significantly less than the L4 at 350 ms and the A10 at 400 ms. If your LLMs and their data fit into memory, then the L4 and A10 would be more cost-effective choices for your needs than the 4090.
See nvidia.com for more details about GPUs that are fast swappers (aka virtualization).
Larger datacentre GPUs are available, but the relative cost is 50 times higher. For example, the A100 and H100 with 80 GB VRAM for use on the very largest models with significant data volumes. Lots of VRAM reduces or eliminates the need for swapping.
The following table shows performance of each GPU for small LLMs, sorted by cost factor. Swap times are shown for larger models, or multiple models.
The Relative Cost column uses the cost of a rented 3060 as the baseline. The cost factors for the other GPUs were computed by asking Grok to take the median of pricing from vendors that service the Canadian market (AWS, Hetzner, Lambda Labs, OVHCloud Canada, RunPod, and Vast.ai), and converting to $CAD.
| GPU Model | Relative Cost | VRAM | Gemma2 9B t/s | DeepSeek 6.7B t/s | Swap Latency ms/layer | Notes |
|---|---|---|---|---|---|---|
| H100 80GB | 85.5 | 80 GB | 140–160 | 180–220 | 6-11 | Enterprise current best. |
| L100 52GB | 22.2 | 52 GB | 135–155 | 175–210 | 1-3 | Enterprise will be best when released. |
| RTX 4090 | 2.0 | 24 GB | 100–115 | 130–150 | ~250 | Top consumer version. |
| RTX 3090 | 2.2 | 24 GB | 80–90 | 110–130 | ~300 | Consumer GPU; strong contender. |
| L4 | 1.5 | 24 GB | 70–80 | 95–115 | ~350 | Datacentre GPU. |
| A10 | 1.8 | 24 GB | 65–75 | 90–110 | ~400 | Datacentre GPU. |
| RTX 4000 Ada | 1.6 | 20 GB | 60–70 | 85–105 | ~500 | Datacentre GPU weak sister. |
| RTX 3060 | 1.0 | 12 GB | 50–60 | 75–90 | ~800 | (Baseline) Consumer GPU: slow swap, limited memory |
The same GPUs are shown below, sorted by speed when running large LLMs optimized for each GPU’s capabilities, using an 8K Context, and quantized to Q4_K_M. Different criteria would yield different results.
| GPU Model | Speed t/s | VRAM | Max Model | Example Model | Notes |
|---|---|---|---|---|---|
| H100 80GB | 110‑130 | 80 GB | 70B+ | Llama 3.1 70B | Largest models; no swap. |
| L100 80GB | 105‑125 | 52 GB | 70B+ | Mixtral 8x22B | Largest models; no swap, highest bandwidth. |
| RTX 4090 | 80‑95 | 24 GB | 34B | Llama 3 34B | Top consumer; near-pro. |
| RTX 3090 | 70‑80 | 24 GB | 30B | DeepSeek-V2 16B | High VRAM; strong consumer. |
| RTX 4000 Ada | 60‑70 | 20 GB | 22B | Codestral 22B | Faster than L4 & A10 because the model chosen is smaller. |
| RTX 3060 | 55‑65 | 12 GB | 13B | GLM-Z1-9B | Smallest LLMs required. |
| L4 | 50‑60 | 24 GB | 30B | Qwen3-Coder 30B | |
| A10 | 45‑55 | 24 GB | 34B | CodeLlama 34B | Full offload; balanced ML. |
Datacentre GPUs
Amazon sells a “generic brand” NVIDIA H100 80 GB for the paltry sum of $38,532.96 (plus $5.54 delivery). Yes, that is the actual price, it is not a mistake. This listing mentioned a warranty. The H100 is about to be unseated by the L100 when it is released in December 2025 at a quarter of the cost of the H100.
Amazon.ca sells a PNY NVIDIA L4 24 GB for $4,928.86, plus $43.35 delivery.
Amazon.ca also sells a “generic brand” NVIDIA Tesla A10 24GB GPU for $4,893.25 CAD on Amazon.ca. I suspect this is a gray market item, so the product likely has no warranty.
GPU Performance vs. Cost
I used a log scale on the cost axis because the enterprise-grade GPUs are so much more expensive. Note that the blue line for latency is different from the other lines: large latency values are undesirable. For all the other lines, higher is better.
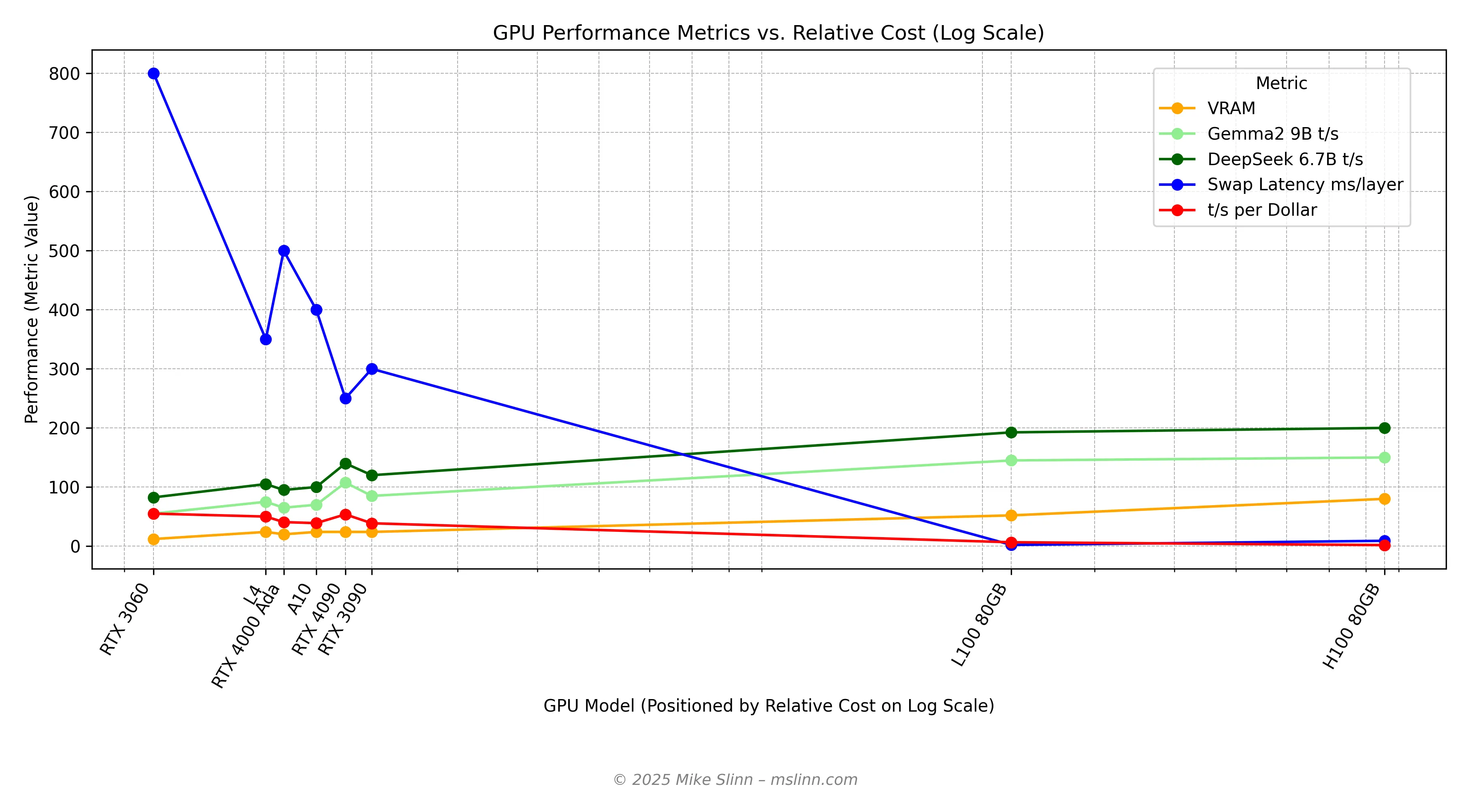
Although the 3060 has the best price/performance, it is too small for hosting most applications involving LLMs with agency and without swapping. Swapping makes every interaction between user and LLM longer. The 3060 works fine if you are patient. How patient you need to be depends on the LLM and data that you are working with.
The L100 (80 GB) has at most 52 GB of memory available for LLMs and data.
Some remarks about the cluster of GPUs (L4, RTX 4000 Ada, A10, RTX 3090):
- The L4 and RTX 4090 offers the best price/performance.
- The RTX 4000 Ada suffers a lot more latency than the others. Prefer the L4 instead.
- The RTX 3090 offers the worst price/performance.
Why Are Consumer-Grade GPUs So Expensive?
It is much cheaper to rent GPUs, as shown in the tables in the previous section. When renting, the cost of a 4090 is only 2x the cost of a 3060, and is actually less expensive than a 3090. This makes the 4090 the best value when renting a remote desktop GPU.
Why do consumer GPUs cost more than low-end datacentre GPUs?
- Datacentre GPUs fit in standard servers, require much less power and do not need video outputs, so they much simpler to make.
- Manufacturers generally receive only 60-75% of the purchase price when sold through retailers. Distributors usually get 3-7%, and retailers get 8-15%.
- Volume pricing; datacentres buy many at once, but consumers buy one at a time.
- Demand by video gamers keeps the prices of consumer GPUs high.
Datacentre-quality GPUs can cost less than a 4090 for similar or better performance with LLMs, as shown in the previous section.
Canadian Renters
The following table shows vendors that provide remote GPU cloud services for AI/ML workloads for users in Canada. These are comparable to European-based instances offered by Scaleway and Hivenet. Some of these datacentres support PIPEDA compliance. Some vendors charge for egress, storage and other factors; those costs are not discussed in this introductory article. Prices are in $CAD.
When you rent a GPU, you also rent the chassis that the GPU resides in, along with the other necessary components (power supply, power, internet connectivity). Keep that in mind when comparing a GPU purchase price against a rental price.
Scaleway and HiveNet both offer compelling service offerings at attractive prices, but they do not have datacentres in North America, which means latency would be a problem for Canadian users.
The table rows for each vendor are sorted by increasing GPU capability for LLMs. We can see that the NVIDIA L4 is a more economical choice than the NVIDIA A10, and it handles LLMs better.
Lambda Labs does not show pricing for the L100 yet, but RunPod does. We will know more next month, after the L100 is released.
| Vendor Name | GPU Model | VRAM | Hourly Rate | Per-Minute Rate | Notes |
|---|---|---|---|---|---|
| AWS | RTX 4000 Ada | 20 GB | ~2.86–4.28 | ~0.048–0.071 | Workstation-grade. |
| NVIDIA A10 | 24 GB | ~2.28–3.42 | ~0.038–0.057 | Balanced for ML/graphics. | |
| NVIDIA L4 | 24 GB | ~1.90 | ~0.032 | Entry-level inference; G5 instances. | |
| Hetzner | RTX 4000 Ada | 20 GB | ~0.81 | ~0.014 | Auction-based; monthly dedicated also available. |
| A10 | 24 GB | ~1.61 | ~0.027 | Auction for short-term; monthly dedicated available. | |
| L4 | 24 GB | ~1.21 | ~0.020 | Auction pricing; dedicated monthly also available. | |
| Lambda Labs | RTX 4090 | 24 GB | 0.88 | ~0.015 | On-demand; no spot interruptions. |
| A100 80GB | 80 GB | 2.63 | ~0.044 | On-demand; Toronto datacentre? | |
| H100 80GB | 80 GB | 4.39 | ~0.073 | Pay-per-minute; private cloud options. | |
| OVHcloud Canada | RTX 4000 Ada | 20 GB | ~3.28–5.47 | ~0.055–0.091 | |
| A10 | 24 GB | ~2.19–3.28 | ~0.036–0.055 | Pay-as-you-go. | |
| L4 | 24 GB | ~1.64 | ~0.027 | Per-minute after 1-hour minimum; Montreal-area datacentre. | |
| RunPod | RTX 4000 Ada | 20 GB | 1.12 | ~0.019 | Scalable to 4x; not per-minute granular, but per-hour. |
| A10 | 24 GB | 0.72–1.16 | ~0.012–0.019 | Hourly blocks; auction for short-term. | |
| L4 | 24 GB | 1.16–1.47 | ~0.019–0.024 | Per-second billing; Canadian availability zones; secure cloud. | |
| L100 | 80 GB | 2.76–4.14 | ~0.046–0.069 | ||
| Vast.ai | RTX 4000 Ada | 20 GB | 0.29–0.74 | ~0.005–0.012 | Marketplace bidding can be 60–80% cheaper. |
| A10 | 24 GB | 0.72–1.16 | ~0.012–0.019 | ||
| L4 | 24 GB | 0.74–1.16 | ~0.012–0.019 |
The above table is wide, so you can only see a portion of it at a time. Drag left with your finger over the above table, or use the horizontal scrollbar and push right to see the rest of the table.
Starlink
Starlink is an option for remote areas that uses satellites to deliver internet service. Its use as permanent infrastructure has become controversial of late.
Starlink's median latency is 25–60 ms in 2025 (down from 76 ms in 2022), with averages of 45 ms for typical U.S./Canadian users. This adds ~50–120 ms per round-trip API call (RTT) to LLM responses, assuming 20–50 ms latency per remote provider.
The extra latency imposed by using satellites for internet access is less than 10% of the total latency when hard-wired connections exist to nearby servers. This is not a significant increase for most situations.
| Number of Remote LLMs | Added Latency | Total Delay | Notes |
|---|---|---|---|
| 1 LLM | 50–60 ms | ~3.05–3.06 s | Single call; negligible impact. |
| 3 LLMs | 150–180 ms | ~3.15–3.18 s | 3 sequential calls; <5% increase. |
| 5 LLMs | 250–300 ms | ~3.25–3.30 s | 5 calls; <10% increase, still quick. |
Bandwidth Calculation
- Payload: 4K–8K tokens/step (~16–32 KB); 5 models/task: ~100–200 KB total.
- Transfer Time: At 25 Mbps, ~32–64 ms (negligible).
- Network round-trip latency: 500–1500 ms/model (0.5-1.5 seconds).
As you can see, network latency dominates transfer time (which is determined by network bandwidth.) However, the time for LLMs to perform processing might be 15 seconds or more. I explore the time to perform processing in Early Draft: Multi-LLM Agent Pipelines
Breakeven Including Internet costs
Let’s consider the cost of a good internet connection throughout Canada. What does breakeven look like in urban, rural and remote areas?
Major Urban Centres
Internet @ $50/month = $600/year
Breakeven: $4,500 ÷ $600 = 7.5 years
Rural Areas
Fixed costs: $4500 GPU plus $500 internet installation fee.
Starlink/fixed wireless internet $110/month = $1440/year.
Breakeven: $5000 ÷ $1440 = 3.5 years
Remote Areas
Assuming internet $110 - $140/month = $2160 - $1320/year plus $500 installation Breakeven: $5000 ÷ $2160 = 2.3 years
Breakeven
Breakeven drops from 13 years to 2.1–5.0 years when internet is the only ongoing cost to consider. In remote areas, buying an RTX 4090 pays off in 2.1 years of 24/7 use. This is roughly equal to the expected lifespan of that product.
For the far north and other remote areas, buying local hardware breaks even in under 3 years. However, if power is available, small local computational clusters would provide much greater reliability.
Conclusion
I assume that the size of models in common use will continue to grow. System components that are reasonable today will be insufficient in a few short years. What we think of as "big" today will be "small" in the future.
The technology for inferencing using LLMs is commoditizing rapidly. Renting remote GPUs is likely to be much more economical, in both the short term and the long term, than buying and installing local GPUs for most users. However, in remote areas where internet service is expensive or unreliable, but electrical power is available, local hardware may be more appropriate.
Usage volume will grow very rapidly by orders of magnitude.
Power efficiency must also improve by orders of magnitude.
References
- Claude Code Is Magnificent, But Claude Desktop Is a Hot Mess
- Gemini vs. Sonnet 3.5 and 4.6 for Meticulous Work
- Google Gemini Code Assist
- Google Antigravity
- Aider: AI Pair Programming in Your Terminal
- AI Planning vs. Waterfall Project Management
- Best Local LLMs for Coding
- Running an LLM on the Windows Ollama app
- Early Draft: Multi-LLM Agent Pipelines
- MiniMax-M2 and Mini-Agent Review
- MiniMax Web Search with ddgr
- LLM Societies
- CodeGPT












