
Published 2024-02-12.
Last modified 2024-02-14.
Time to read: 3 minutes.
llm collection.
The project provides an API offering all the primitives required to build private, context-aware AI applications. It follows and extends the OpenAI API standard, and supports both normal and streaming responses.
The documentation is well written.
PrivateGPT relies on LlamaIndex.
Installation
The Quickstart worked on WSL/Ubuntu and macOS.
While privateGPT is computing an answer, you can check to see if the GPU is doing any of the heavy lifting, or if the CPU is doing the best it can to do all the work.
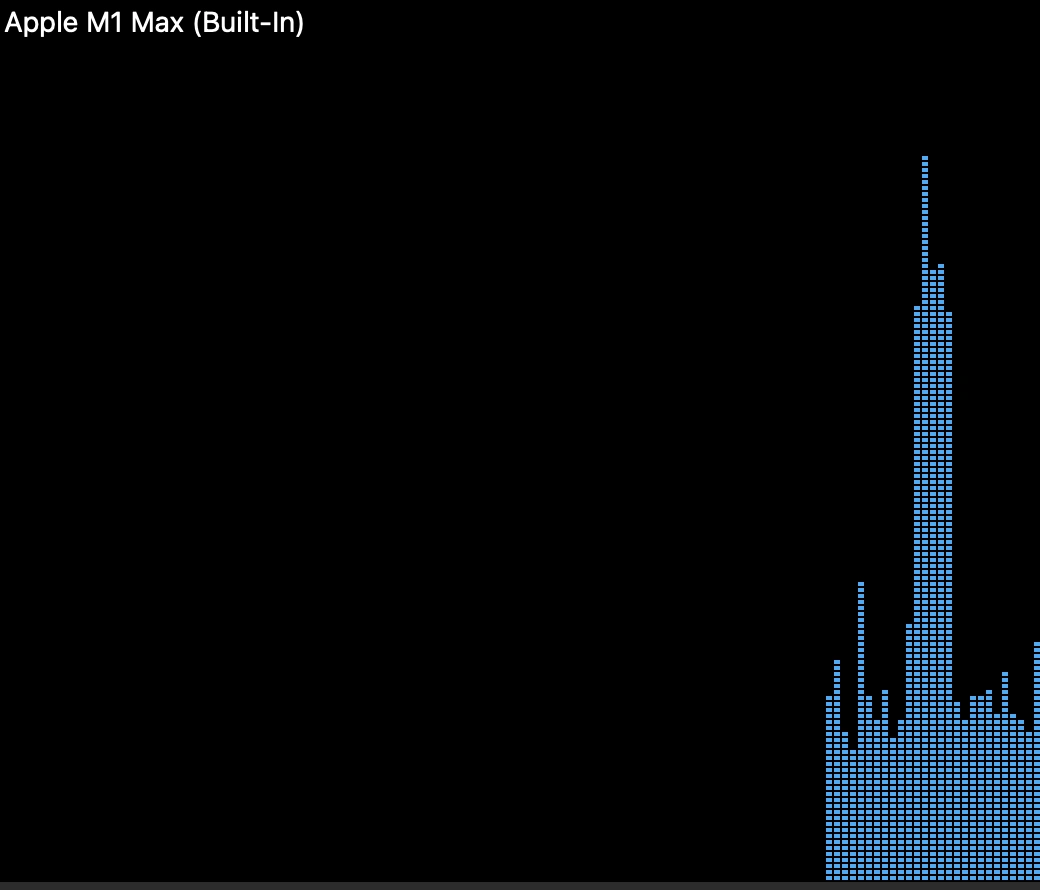
MacBook Pro GPU
On macOS you can see how hard the GPU in your Mac has been working by using the Activity Monitor app, then choosing Window / GPU History.
The image to the right shows the realtime workload for the built-in GPU in a MacBook Pro while privateGPT was computing an answer.
WSL/Ubuntu GPU
I previously wrote about Running LLMs on WSL. It is a mess. Best to use native Ubuntu if NVIDIA drivers are required.
Poetry and Python Virtual Environments
Python virtual environments are a good way to isolate Python programs from each other, so their dependencies do not clash. I wrote about A Python Virtual Environment For Every Project previously, and that article also A Python Virtual Environment For Every Project. The following assumes you read that material.
PrivateGPT is configured
to use Poetry to manage the libraries within the venv.
Installation Commands
This section shows how I installed Private GPT v0.2.0 on WSL/Ubuntu.
First, attempt to deactivate any pre-existing venv.
Do not worry if the error deactivate: command not found appears; that just means there was no active venv.
It is essential that no pre-existing venv be active when attempting to run any poetry subcommand.
$ deactivate # 'deactivate: command not found' is OK :)
Clone the privateGPT Git project:
$ git clone https://github.com/zylon-ai/private-gpt
$ cd privateGPT
The poetry install command creates a new venv containing the dependencies specified
by the project’s poetry.lock.
$ poetry install --with ui,local Creating virtualenv private-gpt in /mnt/f/work/llm/evelyn/privateGPT/.venv Installing dependencies from lock file
Package operations: 148 installs, 1 update, 0 removals
• Installing frozenlist (1.4.1) • Installing idna (3.6) • Installing multidict (6.0.4) • Installing aiosignal (1.3.1) • Installing attrs (23.1.0) • Installing certifi (2023.11.17) • Installing charset-normalizer (3.3.2) • Installing nvidia-nvjitlink-cu12 (12.3.101) • Installing six (1.16.0) • Installing urllib3 (1.26.18) • Installing wrapt (1.16.0) • Installing yarl (1.9.4) • Installing aiohttp (3.9.1) • Installing aiohttp (3.9.1) • Installing deprecated (1.2.14) • Installing dill (0.3.7) • Installing filelock (3.13.1) • Installing fsspec (2023.12.2) • Installing markupsafe (2.1.3) • Installing mpmath (1.3.0) • Installing numpy (1.26.0) • Installing nvidia-cublas-cu12 (12.1.3.1) • Installing nvidia-cusparse-cu12 (12.1.0.106) • Installing packaging (23.2) • Installing python-dateutil (2.8.2) • Installing pytz (2023.3.post1) • Installing pyyaml (6.0.1) • Installing requests (2.31.0) • Installing tqdm (4.66.1) • Installing typing-extensions (4.9.0) • Installing tzdata (2023.3) • Installing h11 (0.14.0) • Installing huggingface-hub (0.19.4) • Installing humanfriendly (10.0) • Installing jinja2 (3.1.2) • Installing multiprocess (0.70.15) • Installing networkx (3.2.1) • Installing nvidia-cuda-cupti-cu12 (12.1.105) • Installing nvidia-cuda-nvrtc-cu12 (12.1.105) • Installing h11 (0.14.0) • Installing huggingface-hub (0.19.4) • Installing humanfriendly (10.0) • Installing jinja2 (3.1.2) • Installing multiprocess (0.70.15) • Installing networkx (3.2.1) • Installing nvidia-cuda-cupti-cu12 (12.1.105) • Installing nvidia-cuda-nvrtc-cu12 (12.1.105) • Installing nvidia-cuda-runtime-cu12 (12.1.105) • Installing nvidia-cudnn-cu12 (8.9.2.26) • Installing nvidia-cufft-cu12 (11.0.2.54) • Installing nvidia-curand-cu12 (10.3.2.106) • Installing nvidia-cusolver-cu12 (11.4.5.107) • Installing nvidia-nccl-cu12 (2.18.1) • Installing nvidia-nvtx-cu12 (12.1.105) • Installing pandas (2.1.4) • Installing protobuf (4.25.1) • Installing pyarrow (14.0.1) • Updating setuptools (68.1.2 -> 69.0.2) • Installing sniffio (1.3.0) • Installing sympy (1.12) • Installing triton (2.1.0) • Installing xxhash (3.4.1) • Installing annotated-types (0.6.0) • Installing anyio (3.7.1) • Installing coloredlogs (15.0.1) • Installing annotated-types (0.6.0) • Installing anyio (3.7.1) • Installing coloredlogs (15.0.1) • Installing datasets (2.14.4) • Installing flatbuffers (23.5.26) • Installing hpack (4.0.0) • Installing httpcore (1.0.2) • Installing hyperframe (6.0.1) • Installing jmespath (1.0.1) • Installing mypy-extensions (1.0.0) • Installing psutil (5.9.6) • Installing pydantic-core (2.14.5) • Installing regex (2023.10.3) • Installing responses (0.18.0) • Installing safetensors (0.4.1) • Installing sentencepiece (0.1.99) • Installing tokenizers (0.15.0) • Installing torch (2.1.2): • Installing accelerate (0.25.0) • Installing botocore (1.34.2) • Installing distro (1.8.0) • Installing distlib (0.3.8) • Installing click (8.1.7) • Installing dnspython (2.4.2) • Installing evaluate (0.4.1). • Installing botocore (1.34.2) • Installing accelerate (0.25.0) • Installing botocore (1.34.2) • Installing botocore (1.34.2) • Installing botocore (1.34.2) • Installing distro (1.8.0) • Installing distlib (0.3.8) • Installing click (8.1.7) • Installing dnspython (2.4.2) • Installing evaluate (0.4.1) • Installing greenlet (3.0.2) • Installing grpcio (1.60.0) • Installing h2 (4.1.0) • Installing httptools (0.6.1) • Installing httpx (0.25.2) • Installing iniconfig (2.0.0) • Installing joblib (1.3.2) • Installing marshmallow (3.20.1) • Installing onnx (1.15.0) • Installing onnxruntime (1.16.3) • Installing pillow (10.1.0) • Installing platformdirs (4.1.0) • Installing pluggy (1.3.0) • Installing pydantic (2.5.2) • Installing python-dotenv (1.0.0) • Installing scipy (1.11.4) • Installing soupsieve (2.5) • Installing starlette (0.27.0) • Installing threadpoolctl (3.2.0) • Installing transformers (4.36.1) • Installing typing-inspect (0.9.0) • Installing uvloop (0.19.0) • Installing watchfiles (0.21.0) • Installing websockets (11.0.3) • Installing aiostream (0.5.2) • Installing beautifulsoup4 (4.12.2) • Installing cfgv (3.4.0) • Installing coverage (7.3.3) • Installing dataclasses-json (0.5.14) • Installing diskcache (5.6.3) • Installing email-validator (2.1.0.post1) • Installing fastapi (0.103.2) • Installing grpcio-tools (1.60.0) • Installing identify (2.5.33) • Installing itsdangerous (2.1.2) • Installing nest-asyncio (1.5.8) • Installing cfgv (3.4.0) • Installing beautifulsoup4 (4.12.2) • Installing cfgv (3.4.0) • Installing aiostream (0.5.2) • Installing beautifulsoup4 (4.12.2) • Installing cfgv (3.4.0) • Installing cfgv (3.4.0) • Installing beautifulsoup4 (4.12.2) • Installing cfgv (3.4.0) • Installing coverage (7.3.3) • Installing dataclasses-json (0.5.14) • Installing diskcache (5.6.3) • Installing email-validator (2.1.0.post1) • Installing fastapi (0.103.2) • Installing grpcio-tools (1.60.0) • Installing identify (2.5.33) • Installing itsdangerous (2.1.2) • Installing nest-asyncio (1.5.8) • Installing nltk (3.8.1) • Installing nodeenv (1.8.0) • Installing openai (1.5.0) • Installing optimum (1.16.1) • Installing orjson (3.9.10) • Installing pathspec (0.12.1) • Installing portalocker (2.8.2) • Installing pydantic-extra-types (2.2.0) • Installing pydantic-settings (2.1.0) • Installing pytest (7.4.3) • Installing python-multipart (0.0.6) • Installing s3transfer (0.9.0) • Installing scikit-learn (1.3.2) • Installing sqlalchemy (2.0.23) • Installing tenacity (8.2.3) • Installing tiktoken (0.5.2) • Installing torchvision (0.16.2) • Installing ujson (5.9.0) • Installing uvicorn (0.24.0.post1) • Installing virtualenv (20.25.0) • Installing black (22.12.0) • Installing boto3 (1.34.2) • Installing injector (0.21.0) • Installing llama-cpp-python (0.2.23) • Installing black (22.12.0) • Installing boto3 (1.34.2) • Installing injector (0.21.0) • Installing llama-cpp-python (0.2.23) • Installing llama-index (0.9.3) • Installing mypy (1.7.1) • Installing pre-commit (2.21.0) • Installing pypdf (3.17.2) • Installing pytest-asyncio (0.21.1) • Installing pytest-cov (3.0.0) • Installing qdrant-client (1.7.0) • Installing ruff (0.1.8) • Installing sentence-transformers (2.2.2) • Installing types-pyyaml (6.0.12.12) • Installing watchdog (3.0.0)
Installing the current project: private-gpt (0.2.0)
Now download the embedding model and tokenizer.
The first line of scripts/setup is the
shebang for running Python:
#!/usr/bin/env python3
This means we do not need to specify python3 on the command line in order to run the setup script.
$ poetry run scripts/setup 13:40:58.082 [INFO ] private_gpt.settings.settings_loader - Starting application with profiles=['default'] Downloading embedding BAAI/bge-small-en-v1.5 Fetching 13 files: 100%|███████████████████████████████████████████████████| 13/13 [00:00<00:00, 67.85it/s] Embedding model downloaded! Downloading LLM mistral-7b-instruct-v0.2.Q4_K_M.gguf LLM model downloaded! Downloading tokenizer mistralai/Mistral-7B-Instruct-v0.2 Tokenizer downloaded! Setup done
The default model is downloaded from HuggingFace,
TheBloke/Mistral-7B-Instruct-v0.2-GGUF (4.37 GB).
The default model and maximum number of tokens is defined in
settings.yaml,
which at this point looks like:
llm: mode: local # Should be matching the selected model max_new_tokens: 512 context_window: 3900 tokenizer: mistralai/Mistral-7B-Instruct-v0.2
While it is possible to edit settings.yaml,
it is better to edit the overlay, settings-local.yaml,
then set the PGPT_PROFILES environment variable to use the overlaid settings.
The privateGPT docs
also talk about a file called settings-cuda.yaml,
which I imagine would contain configuration specific to NVIDIA GPUs.
However, that file was not provided, and can be ignored.
I found that privateGPT used my NVIDIA RTX 3060 video card automagically.
Command-Line Subshell
If you want to debug PrivateGPT from the command-line, you could launch a Poetry subshell,
so the dependencies managed by Poetry are available.
Use the poetry shell command for this.
$ poetry shell Creating virtualenv private-gpt in /mnt/f/work/llm/evelyn/privateGPT/.venv Spawning shell within /mnt/f/work/privateGPT/.venv . /mnt/f/work/privateGPT/.venv/bin/activate . /mnt/f/work/privateGPT/.venv/bin/activate
$ irb irb(main):001> CTRL-D
$ CTRL-D
Of course, you could also use poetry run for this purpose:-
$ poetry run irb irb(main):001>
Running PrivateGPT
Finally I launched the privateGPT API server and the gradio UI using the overlaid settings:
$ PGPT_PROFILES=local poetry run python -m private_gpt 11:15:00.269 [INFO ] private_gpt.settings.settings_loader - Starting application with profiles=['default'] 11:15:20.216 [INFO ] private_gpt.components.llm.llm_component - Initializing the LLM in mode=local llama_model_loader: loaded meta data with 24 key-value pairs and 291 tensors from /mnt/f/work/llm/evelyn/privateGPT/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf (version GGUF V3 (latest)) llama_model_loader: - tensor 0: token_embd.weight q4_K [ 4096, 32000, 1, 1 ] llama_model_loader: - tensor 1: blk.0.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 2: blk.0.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 3: blk.0.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 4: blk.0.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 5: blk.0.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 6: blk.0.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 7: blk.0.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 8: blk.0.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 9: blk.0.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 10: blk.1.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 11: blk.1.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 12: blk.1.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 13: blk.1.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 14: blk.1.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 15: blk.1.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 16: blk.1.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 17: blk.1.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 18: blk.1.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 19: blk.2.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 20: blk.2.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 21: blk.2.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 22: blk.2.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 23: blk.2.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 24: blk.2.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 25: blk.2.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 26: blk.2.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 27: blk.2.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 28: blk.3.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 29: blk.3.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 30: blk.3.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 31: blk.3.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 32: blk.3.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 33: blk.3.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 34: blk.3.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 35: blk.3.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 36: blk.3.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 37: blk.4.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 38: blk.4.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 39: blk.4.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 40: blk.4.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 41: blk.4.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 42: blk.4.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 43: blk.4.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 44: blk.4.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 45: blk.4.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 46: blk.5.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 47: blk.5.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 48: blk.5.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 49: blk.5.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 50: blk.5.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 51: blk.5.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 52: blk.5.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 53: blk.5.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 54: blk.5.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 55: blk.6.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 56: blk.6.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 57: blk.6.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 58: blk.6.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 59: blk.6.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 60: blk.6.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 61: blk.6.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 62: blk.6.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 63: blk.6.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 64: blk.7.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 65: blk.7.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 66: blk.7.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 67: blk.7.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 68: blk.7.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 69: blk.7.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 70: blk.7.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 71: blk.7.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 72: blk.7.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 73: blk.8.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 74: blk.8.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 75: blk.8.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 76: blk.8.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 77: blk.8.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 78: blk.8.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 79: blk.8.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 80: blk.8.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 81: blk.8.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 82: blk.9.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 83: blk.9.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 84: blk.9.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 85: blk.9.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 86: blk.9.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 87: blk.9.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 88: blk.9.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 89: blk.9.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 90: blk.9.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 91: blk.10.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 92: blk.10.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 93: blk.10.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 94: blk.10.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 95: blk.10.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 96: blk.10.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 97: blk.10.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 98: blk.10.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 99: blk.10.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 100: blk.11.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 101: blk.11.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 102: blk.11.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 103: blk.11.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 104: blk.11.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 105: blk.11.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 106: blk.11.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 107: blk.11.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 108: blk.11.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 109: blk.12.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 110: blk.12.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 111: blk.12.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 112: blk.12.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 113: blk.12.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 114: blk.12.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 115: blk.12.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 116: blk.12.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 117: blk.12.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 118: blk.13.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 119: blk.13.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 120: blk.13.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 121: blk.13.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 122: blk.13.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 123: blk.13.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 124: blk.13.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 125: blk.13.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 126: blk.13.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 127: blk.14.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 128: blk.14.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 129: blk.14.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 130: blk.14.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 131: blk.14.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 132: blk.14.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 133: blk.14.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 134: blk.14.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 135: blk.14.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 136: blk.15.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 137: blk.15.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 138: blk.15.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 139: blk.15.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 140: blk.15.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 141: blk.15.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 142: blk.15.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 143: blk.15.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 144: blk.15.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 145: blk.16.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 146: blk.16.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 147: blk.16.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 148: blk.16.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 149: blk.16.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 150: blk.16.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 151: blk.16.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 152: blk.16.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 153: blk.16.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 154: blk.17.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 155: blk.17.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 156: blk.17.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 157: blk.17.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 158: blk.17.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 159: blk.17.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 160: blk.17.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 161: blk.17.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 162: blk.17.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 163: blk.18.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 164: blk.18.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 165: blk.18.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 166: blk.18.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 167: blk.18.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 168: blk.18.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 169: blk.18.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 170: blk.18.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 171: blk.18.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 172: blk.19.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 173: blk.19.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 174: blk.19.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 175: blk.19.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 176: blk.19.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 177: blk.19.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 178: blk.19.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 179: blk.19.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 180: blk.19.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 181: blk.20.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 182: blk.20.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 183: blk.20.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 184: blk.20.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 185: blk.20.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 186: blk.20.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 187: blk.20.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 188: blk.20.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 189: blk.20.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 190: blk.21.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 191: blk.21.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 192: blk.21.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 193: blk.21.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 194: blk.21.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 195: blk.21.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 196: blk.21.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 197: blk.21.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 198: blk.21.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 199: blk.22.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 200: blk.22.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 201: blk.22.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 202: blk.22.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 203: blk.22.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 204: blk.22.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 205: blk.22.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 206: blk.22.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 207: blk.22.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 208: blk.23.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 209: blk.23.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 210: blk.23.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 211: blk.23.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 212: blk.23.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 213: blk.23.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 214: blk.23.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 215: blk.23.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 216: blk.23.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 217: blk.24.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 218: blk.24.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 219: blk.24.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 220: blk.24.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 221: blk.24.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 222: blk.24.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 223: blk.24.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 224: blk.24.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 225: blk.24.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 226: blk.25.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 227: blk.25.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 228: blk.25.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 229: blk.25.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 230: blk.25.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 231: blk.25.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 232: blk.25.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 233: blk.25.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 234: blk.25.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 235: blk.26.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 236: blk.26.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 237: blk.26.attn_v.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 238: blk.26.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 239: blk.26.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 240: blk.26.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 241: blk.26.ffn_down.weight q4_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 242: blk.26.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 243: blk.26.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 244: blk.27.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 245: blk.27.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 246: blk.27.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 247: blk.27.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 248: blk.27.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 249: blk.27.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 250: blk.27.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 251: blk.27.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 252: blk.27.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 253: blk.28.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 254: blk.28.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 255: blk.28.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 256: blk.28.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 257: blk.28.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 258: blk.28.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 259: blk.28.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 260: blk.28.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 261: blk.28.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 262: blk.29.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 263: blk.29.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 264: blk.29.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 265: blk.29.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 266: blk.29.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 267: blk.29.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 268: blk.29.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 269: blk.29.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 270: blk.29.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 271: blk.30.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 272: blk.30.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 273: blk.30.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 274: blk.30.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 275: blk.30.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 276: blk.30.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 277: blk.30.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 278: blk.30.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 279: blk.30.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 280: blk.31.attn_q.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 281: blk.31.attn_k.weight q4_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 282: blk.31.attn_v.weight q6_K [ 4096, 1024, 1, 1 ] llama_model_loader: - tensor 283: blk.31.attn_output.weight q4_K [ 4096, 4096, 1, 1 ] llama_model_loader: - tensor 284: blk.31.ffn_gate.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 285: blk.31.ffn_up.weight q4_K [ 4096, 14336, 1, 1 ] llama_model_loader: - tensor 286: blk.31.ffn_down.weight q6_K [ 14336, 4096, 1, 1 ] llama_model_loader: - tensor 287: blk.31.attn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 288: blk.31.ffn_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 289: output_norm.weight f32 [ 4096, 1, 1, 1 ] llama_model_loader: - tensor 290: output.weight q6_K [ 4096, 32000, 1, 1 ] llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = llama llama_model_loader: - kv 1: general.name str = mistralai_mistral-7b-instruct-v0.2 llama_model_loader: - kv 2: llama.context_length u32 = 32768 llama_model_loader: - kv 3: llama.embedding_length u32 = 4096 llama_model_loader: - kv 4: llama.block_count u32 = 32 llama_model_loader: - kv 5: llama.feed_forward_length u32 = 14336 llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128 llama_model_loader: - kv 7: llama.attention.head_count u32 = 32 llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 8 llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010 llama_model_loader: - kv 10: llama.rope.freq_base f32 = 1000000.000000 llama_model_loader: - kv 11: general.file_type u32 = 15 llama_model_loader: - kv 12: tokenizer.ggml.model str = llama llama_model_loader: - kv 13: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<... llama_model_loader: - kv 14: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000... llama_model_loader: - kv 15: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ... llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32 = 1 llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32 = 2 llama_model_loader: - kv 18: tokenizer.ggml.unknown_token_id u32 = 0 llama_model_loader: - kv 19: tokenizer.ggml.padding_token_id u32 = 0 llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 22: tokenizer.chat_template str = {{ bos_token }}{% for message in mess... llama_model_loader: - kv 23: general.quantization_version u32 = 2 llama_model_loader: - type f32: 65 tensors llama_model_loader: - type q4_K: 193 tensors llama_model_loader: - type q6_K: 33 tensors llm_load_vocab: special tokens definition check successful ( 259/32000 ). llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = llama llm_load_print_meta: vocab type = SPM llm_load_print_meta: n_vocab = 32000 llm_load_print_meta: n_merges = 0 llm_load_print_meta: n_ctx_train = 32768 llm_load_print_meta: n_embd = 4096 llm_load_print_meta: n_head = 32 llm_load_print_meta: n_head_kv = 8 llm_load_print_meta: n_layer = 32 llm_load_print_meta: n_rot = 128 llm_load_print_meta: n_gqa = 4 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-05 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: n_ff = 14336 llm_load_print_meta: n_expert = 0 llm_load_print_meta: n_expert_used = 0 llm_load_print_meta: rope scaling = linear llm_load_print_meta: freq_base_train = 1000000.0 llm_load_print_meta: freq_scale_train = 1 llm_load_print_meta: n_yarn_orig_ctx = 32768 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: model type = 7B llm_load_print_meta: model ftype = mostly Q4_K - Medium llm_load_print_meta: model params = 7.24 B llm_load_print_meta: model size = 4.07 GiB (4.83 BPW) llm_load_print_meta: general.name = mistralai_mistral-7b-instruct-v0.2 llm_load_print_meta: BOS token = 1 '<s>' llm_load_print_meta: EOS token = 2 '</s>' llm_load_print_meta: UNK token = 0 '<unk>' llm_load_print_meta: PAD token = 0 '<unk>' llm_load_print_meta: LF token = 13 '<0x0A>' llm_load_tensors: ggml ctx size = 0.12 MiB llm_load_tensors: mem required = 4165.48 MiB
I pointed my web browser at localhost:8001 and saw:
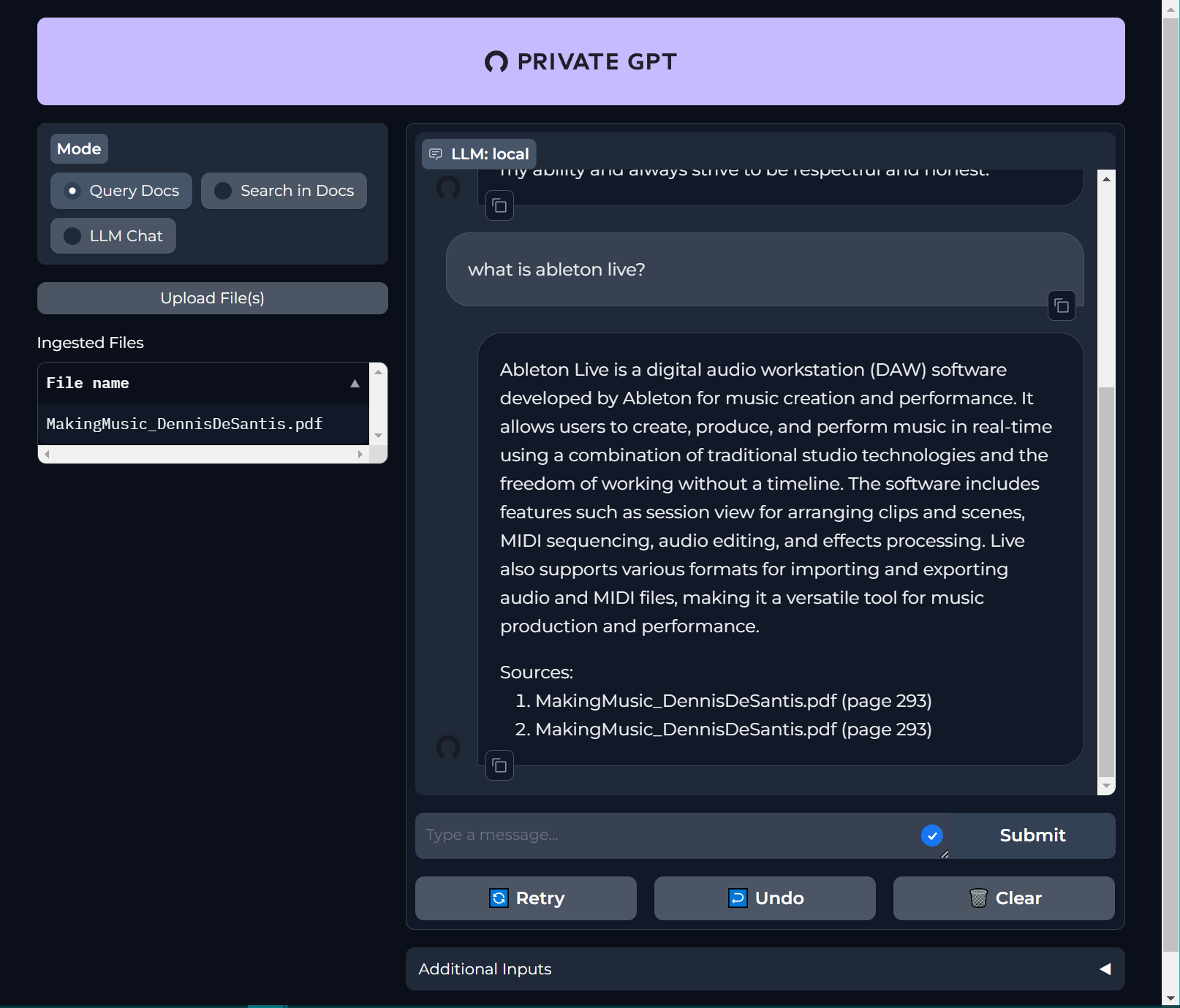
After uploading this PDF, I asked a question that the PDF had the answer to. Private GPT gave the page number that it got the answer from. The reference was duplicated.
I uploaded another PDF, and asked the same question again.
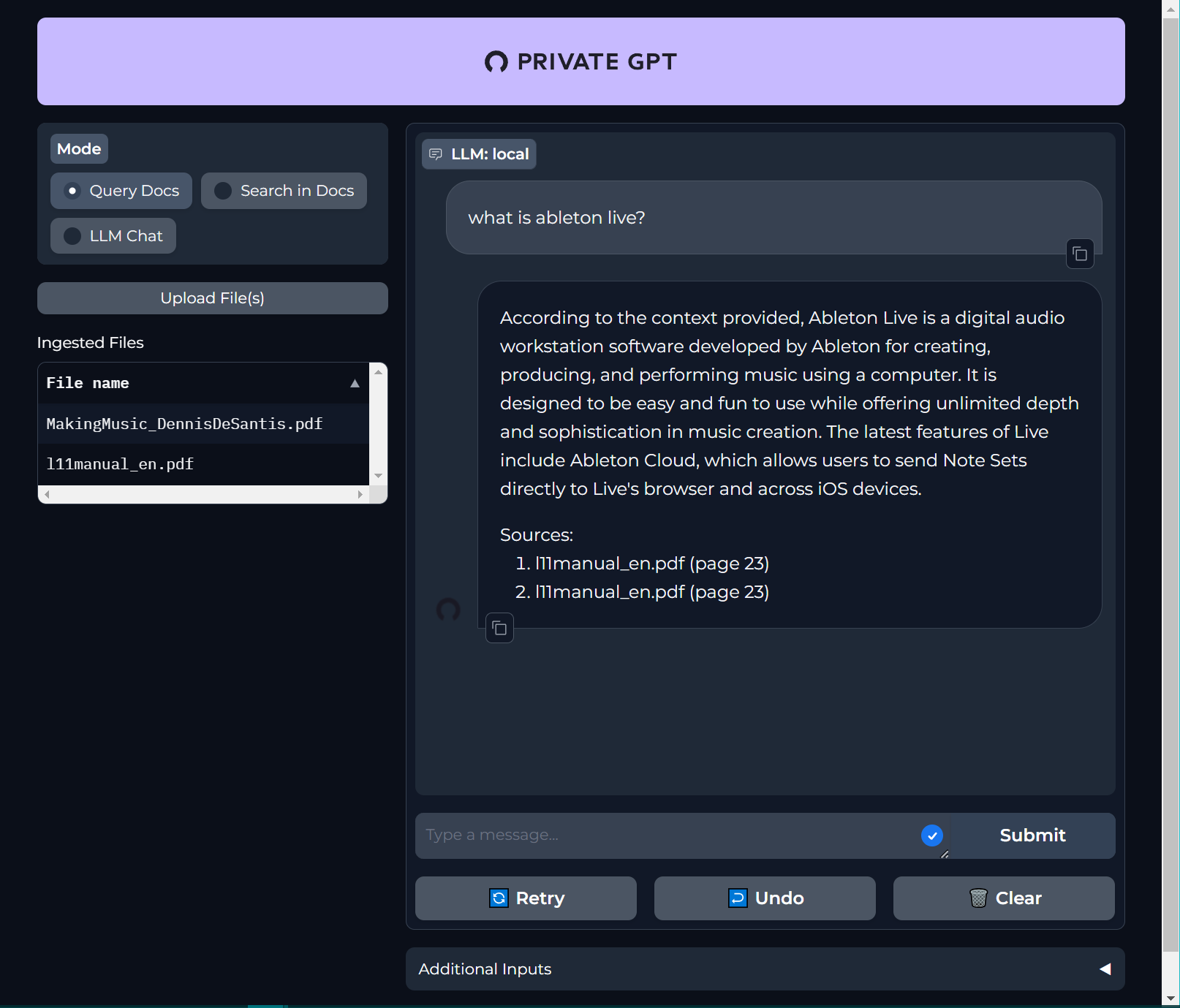
The previous explanation and reference was ignored, and unfortunately only the new document was searched. Again, the reference was duplicated. I wonder if it is possible to suppress the introductory phrase "According to the context provided".
Quiet Launch Script
This bash script swallows most of the spurious messages that privateGPT spews all over the floor each time it runs.
#!/bin/bash
function help {
echo "$(basename "$0") - Run privateGPT
OPTIONS:
-h display this help information
-v show all messages
If you want to monitor your GPU activity, run one of the following:
nvtop
watch -d gpustat
"
exit 1
}
cd "$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )" || exit
# Disable any activated virtual environment
# See https://mslinn.com/blog/2021/04/09/python-venvs.html#pvenv
VENV="$( dirname "$( which virtualenv)" )"
if [ ! "$VENV" == /usr/bin ]; then source "$VENV/activate" && deactivate 2>/; fi
# export PGPT_PROFILES=local,logger
export PGPT_PROFILES=local
unset HIDDEN VERBOSE
if [ "$1" == -v ]; then VERBOSE=true; shift; fi
if [ "$1" == -h ]; then help; fi
echo "privateGPT serving on http://localhost:8001 (Press CTRL+C to quit)"
if [ "$VERBOSE" ]; then
poetry run python -m private_gpt
else
export UVICORN_LOG_LEVEL=WARN
# Set up filter for grep to suppress noisy stderr
for X in 'Initializing the LLM in mode=local' \
'Initializing the embedding model in mode=' \
llama_index.indices.loading \
'llama_new_context_with_model\:' \
'llama_build_graph\:' \
'llm_load_print_meta\:' \
'llm_load_tensors\:' \
'llm_load_vocab\:' \
'llama_model_loader\:' \
'Mounting the gradio UI, at path=' \
uvicorn.access \
uvicorn.error; do
if [ "$HIDDEN" ]; then
HIDDEN="$HIDDEN\|$X"
else
HIDDEN="$X"
fi
done
# echo "$HIDDEN"
SUPPRESS_WARNINGS=-Wignore
poetry run python $SUPPRESS_WARNINGS -m private_gpt 2> >(grep -v "$HIDDEN")
fi
Changing the Apology
The PrivateGPT’s default apology for not knowing the answer to a question was constructed from static text, followed by a directory of documents in the corpus. My test corpus only had 2 PDFs, as shown:
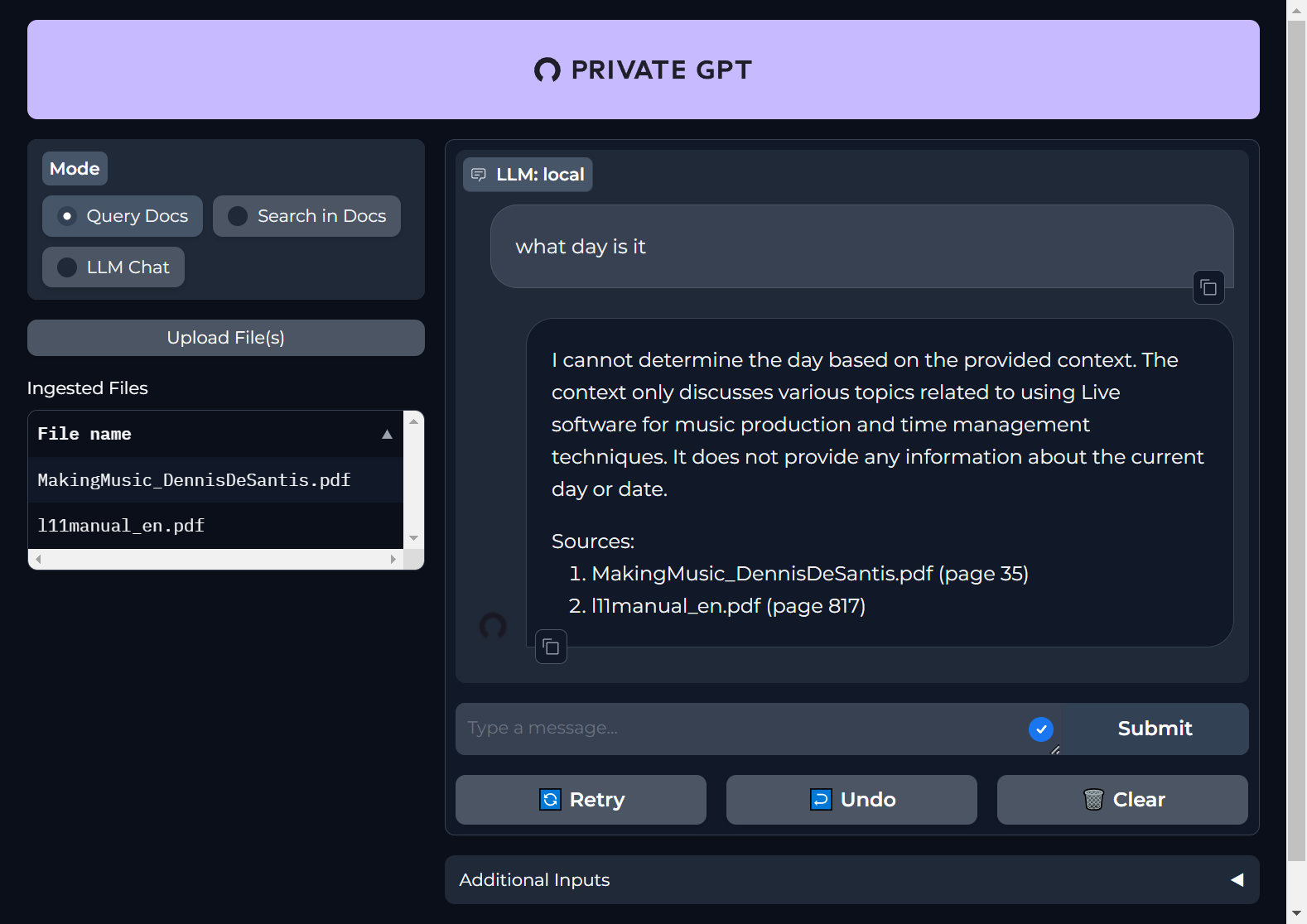
I find it strange that a message stating no answer was to be had cited specific page numbers for each document in the corpus.
To change the prompt, edit settings.yaml and change:
default_query_system_prompt: >
You can only answer questions about the provided context.
If you know the answer but it is not based in the provided context, don't provide
the answer, just state the answer is not in the context provided.
Into this:
default_query_system_prompt: >
You can only answer questions about the provided context.
If you know the answer but it is not based in the provided context, don't provide
the answer, just state the following as the response: "Sorry, I do not know."
Chunking
PrivateGPT splits documents in chunks
(LlamaIndex calls them nodes).
You can get a sense of the chunks by typing the following incantation; some sample output is shown.
Page_label is the page number shown in the document.
$ curl localhost:8001/v1/ingest/list | jq ... { "object": "ingest.document", "doc_id": "d0d4aef0-c28d-48e0-ae92-ec16ec2c8806", "doc_metadata": { "page_label": "141", "file_name": "l11manual_en.pdf" } }, { "object": "ingest.document", "doc_id": "6a76e36b-0e3f-453d-886b-bd070ddfe383", "doc_metadata": { "page_label": "27", "file_name": "l11manual_en.pdf" } }, { "object": "ingest.document", "doc_id": "adc8d60f-9b4b-43ea-8fe3-b8a740e8058b", "doc_metadata": { "page_label": "59", "file_name": "l11manual_en.pdf" } }...
The above privateGPT API is documented here, and the List Ingested call is documented here.
Videos
References












